The Shape of a Question: Teaching SQL to Understand Intent

There’s a particular frustration that hits when you’re staring at a dataset, knowing exactly what you want… conceptually... but it's not "shaped" like a query, yet. It's like a glimpse of a shadow, always ducking around the corner before you can fully conceptualize or articulate it.
How to convert your shadow fragment into a language a structured system understands (SQL, is the king of structured declarative languages, after all) - and the messier that data is (who doesn't have this problem), it just compounds the issue.
You want urgent issues.
But the data says:
priority_level = 3- or
escalated = true - or
description LIKE '%critical%' - or a regex that slowly becomes a haunted house
So you write the regex. You chain the ORs. You catch 80% of what you meant.
Close enough.
Except it isn’t.
Because next week someone writes “this needs to be handled immediately” and your carefully-tuned pattern misses it entirely.
And now you’re back in the weeds, duct-taping meaning onto syntax.
You declaration was only slightly more effective than Michael Scott's bankruptcy announcement.
The gap between intent and implementation
This is a recurring problem I’ve been circling for years: the distance between what we mean and what we can express in formal systems.
It shows up everywhere:
- In data viz, where you want to “see the trends” but end up hand-configuring axes, bins, and aggregations (insert obligatory Bret Victor reference here)
- In flow-based programming, where you want to “transform this data” visually but end up debugging edge cases in coercion and schema drift
- In search, where you want “documents like this one” but end up maintaining keyword taxonomies like it’s 2009
It's just another edge to the ever rotating hexagon of "observability" that I've been trying to decode my whole career.
The pattern is consistent:
We have conceptual clarity…
…and syntactic friction.
SQL is still one of the best tools humans have ever made for thinking about data. Declarative. Composable. Hard-earned. Especially for someone who thinks in shapes and colors... it has a structure, an almost kinesthetic quality. The data, the queries - like 3 dimensional Tetris.
But it’s a tool from an era where computers were expensive and humans were cheap.
So we meticulously specify exactly what we want — because the machine can’t infer anything.
That constraint is loosening.
Not disappearing (precision still matters) — but loosening.
And I’m interested in what happens when the boundary between intent and implementation becomes… permeable.
LARS: an experiment in 'semantic SQL'
I’ve been building something I’m calling LARS (Language-Augmented Relational SQL).
The premise is simple, almost naive:
What if SQL operators could understand intent, not just match patterns?
SELECT *
FROM support_tickets
WHERE description MEANS 'urgent customer issue';
MEANS is not string matching.
It’s semantic judgment.
It’s “does this text align with this concept?” — without you having to enumerate every possible phrasing of urgency.
No brittle keyword lists. No taxonomies. No regex funeral.
Just… ask for what you want.
Tools. Good tools. Tools that fit your hands.
There’s a type of “tool upgrade” that changes your output forever.
Not because it’s faster.
But because the creative ceiling rises.
You stop fighting the tool and start shaping artifacts.
This is what I’m aiming at with LARS: letting SQL stay SQL… while giving it a new dimension: meaning.
Okay, but what is it?
LARS is a SQL query layer that speaks the PostgreSQL wire protocol.
So you can connect with your normal SQL client — DataGrip, DBeaver, psql, Tableau — and run queries like it’s “just another database.”
Except it isn’t really a database.
It sits in front of your data sources and federates through DuckDB (so if DuckDB can read it, LARS can reason about it). That includes Postgres / MySQL / BigQuery / Snowflake / S3 / files / etc.
Your data stays where it is.
The intelligence comes to it.
And when semantic operators get invoked, LARS runs those judgments through an LLM, caches results, tracks cost, and returns a normal result set.
No notebooks. No orchestration code. No “AI sidecar pipeline.”
Just SQL that suddenly has a few new verbs.
A SQL "Intelligence proxy router" of sorts.
The operator vocabulary
Once you have the primitive, you can build a vocabulary.
A few examples:
Filtering by concept
SELECT * FROM products
WHERE description MEANS 'eco-friendly';
Contradictions / compliance vibes
SELECT *
FROM disclosures
WHERE statement CONTRADICTS 'no material changes';
Scoring relevance
SELECT
title,
description ABOUT 'sustainability' AS relevance
FROM reports
ORDER BY relevance DESC;
Semantic aggregation
SELECT
category,
SUMMARIZE(reviews) AS summary
-- or the more succinct: TLDR(reviews)
FROM feedback
GROUP BY category;
Auto-topic grouping (yes, really)
SELECT TOPICS(title, 5) AS topic,
COUNT(1) AS count
FROM articles
GROUP BY topic;
The escape hatch: ASK
SELECT
product_name,
ASK('Is this suitable for children? yes/no', description) AS kid_friendly
FROM products;
ASK is where it gets philosophically interesting.
It’s not a fixed operator.
It’s any question you can articulate.
The data becomes… conversational.
On observability and trust
LLM systems have a well-known problem:
opacity.
How do you trust the output? Debug it? Understand cost? Explain “why” to your future self?
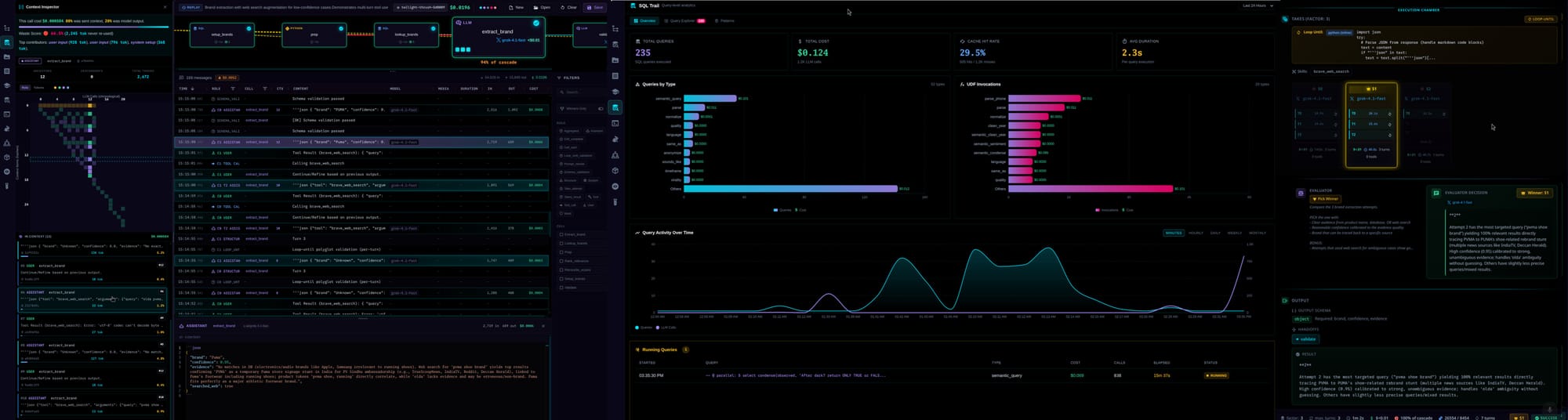
So LARS logs everything.
Every semantic operation is queryable — prompts, responses, tokens, cost, latency, cache hits — in tables like all_data / sql_query_log.
So you can literally query the queries:
SELECT
model,
SUM(cost) AS total_cost,
AVG(duration_ms) AS avg_latency
FROM all_data
WHERE is_sql_udf = true
GROUP BY model
ORDER BY total_cost DESC;
This isn’t optional.
If semantic operations are going to belong in real workflows, they need to be inspectable.
The magic needs receipts.
This isn't just "traces" either - it's that and more, they can tell you WHAT happened, but very few can try to tell you WHY.
Wait, it gets weirder: the workflow engine underneath
Semantic SQL is the shiny surface.
Underneath, LARS is also a declarative agent/workflow system — because every LLM project eventually becomes some variant of:
- retry loops
- validation hacks
- “please output valid JSON” pleading
- prompt mutation spaghetti
Y'all know that I love my "flow based programming" style node and line systems, and it's cool that more LLM systems are falling into this problem, but the graph IS the topology, and if you have some retry loops or conditional logic, after awhile any non-trivial system becomes a mess of boxes and spaghetti. So I designed LARS orchestration engine around "keeping the spaghetti in the bowl". A single step can do it's own loops, retries, refinments, parallel contests - and all that gets passed is the outcome - making your topology much more like some linear branches instead of a thorn bush. Encapsulated complexity.
LARS has a notion of cascades (YAML-defined workflows) and takes (run N variants in parallel, then pick a winner).
Instead of serial retries hoping one succeeds, you can run multiple attempts concurrently and auto select the best output — same cost class, better reliability, and (often) faster wall-clock time.
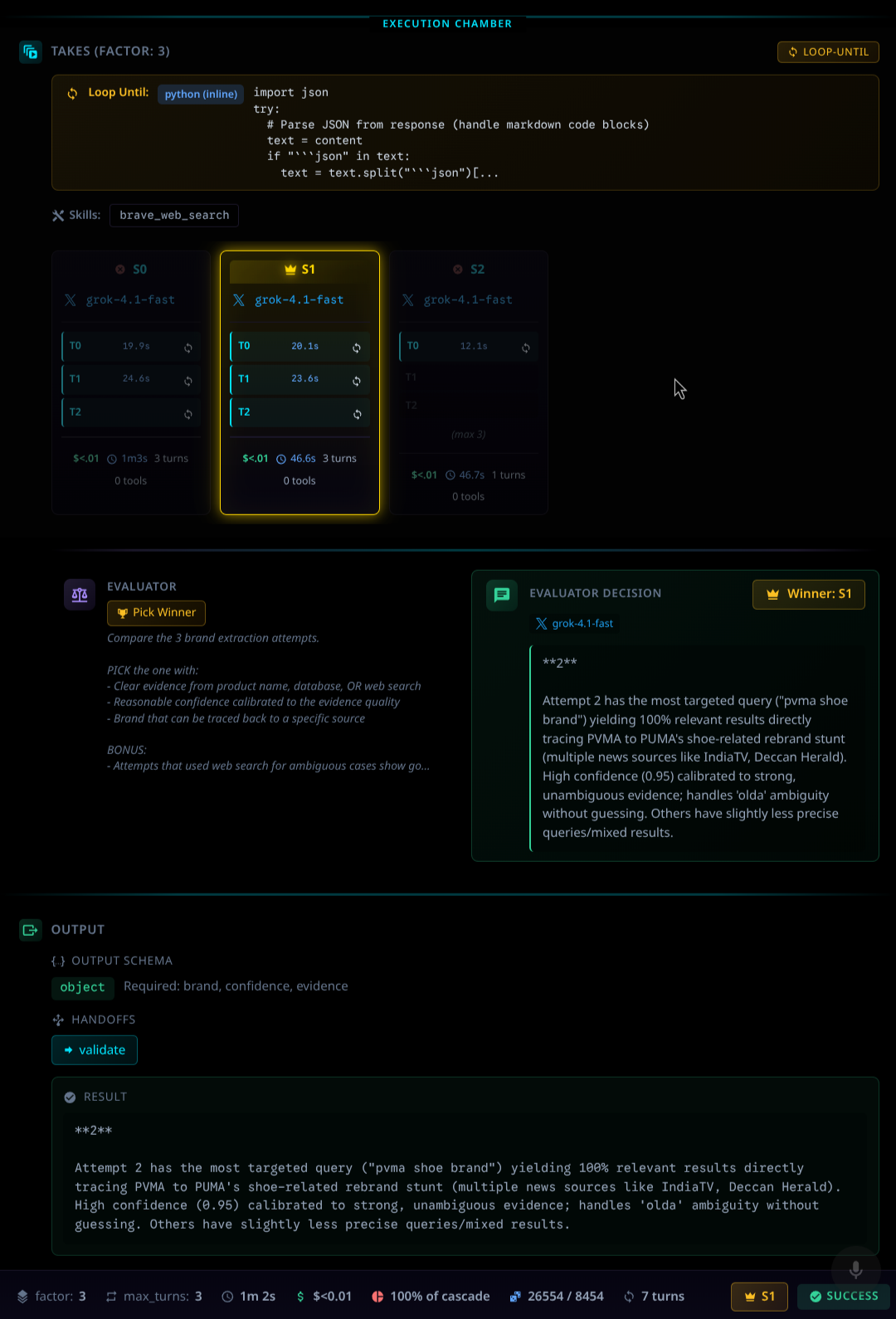
This is the part of LARS that connects directly to the broader “rabbit hole” of stuff I keep building: tools that make complex systems more observable and more human to operate.
Semantic SQL is just a very ergonomic entrance. When the "tool handle fits your hand" vibes.
What this isn’t
LARS isn’t “text-to-SQL” (type a question, the AI writes a query).
Those systems are cool (and it can do that) - but they solve a different problem: query generation from natural language.
LARS assumes you know SQL.
It just gives SQL new words.Verbs mostly...
Also: Again, LARS isn’t a database, technically. It's a SQL workspace for getting shit done. The aether between your data and you understanding of said data. A "surface". I fully expect you to save your outputs back where they came from.
It’s a protocol server / query layer that can sit in front of DuckDB locally and federate out to everything else.
Your data stays home.
LARS just makes the queries smarter and... more interesting. What kind of questions could you ask it now?
SELECT sentiment(comment),
extract(comment, 'product_mentioned')
FROM feedback
WHERE comment MEANS 'asking for refund without saying refund';Why now?
Because the old constraint — “the machine can only do what you precisely specify” — is getting softer.
And I think the next generation of data tooling isn’t about building “AI features”…
…it’s about making intent a first-class input.
Dashboards are not the endgame.
Understanding is.
Quick start (local)
If you want to try it locally, the shortest path looks like:
pip install larsql
export OPENROUTER_API_KEY=sk-or-v1-...
# spin up clickhouse for isolated caching/logging/reporting
docker run -d \
--name lars-clickhouse \
--ulimit nofile=262144:262144 \
-p 8123:8123 -p 9000:9000 -p 9009:9009 \
-v clickhouse-data:/var/lib/clickhouse \
-v clickhouse-logs:/var/log/clickhouse-server \
-e CLICKHOUSE_USER=lars \
-e CLICKHOUSE_PASSWORD=lars \
clickhouse/clickhouse-server:25.11
lars init my_lars_project
cd my_lars_project
lars db init
lars serve sql --port 15432
psql postgresql://localhost:15432/default
# optional UI
lars serve studio
# http://localhost:5050
Heads up: default auth is currently lars / lars. (Proper auth coming soon.)
Links
- https://larsql.com — docs + operator list
- https://github.com/ryrobes/larsql — source
- https://rvbbit.com — shared DNA
This is early-stage, WIP "definitely-has-rough-edges" software.
But it’s usable. And I’ve been running it daily.
If the premise resonates — give it a spin.
Keep those shapes spinning, friends.